Efficient Novelty Detection Methods for Early Warning of Potential Fatal Diseases

Introduction
An early warning approach in healthcare is an algorithm that provides information about upcoming risks to susceptible people before a Critical Health Episode occurs. This enables action to be taken to reduce possible harm and, in some situations, prevent it from occurring. Therefore, it is of great importance to the reduction of mortality in healthcare. Acute Hypotensive Episodes (AHE) and Tachycardia Episodes (TE) are two of the most dangerous Critical Health Episodes in the Intensive Care Units.
Acute Hypotensive Episodes (AHE): Any interval of 30 minutes during which at least 90% of the Mean Arterial blood Pressure (MAP) values are below 60 mmHg (millimeters of mercury)
Tachycardia Episodes (TE): Any interval of 30 minutes during which at least 90% of Heart Rate (HR) measurements are over 100 bpm (beats per minute)
Proposed Method
In general, existing warning systems for AHE and TE early prediction typically have limited performance and high computational costs in real-time alerting when dealing with large amounts of data. So, this work presents MIG-LightGBM, a highly efficient warning system based on a feature selection process with Mutual Information Gain (MIG) and an episode classification approach with the predictive model Light Gradient Boosting Machine (LightGBM)
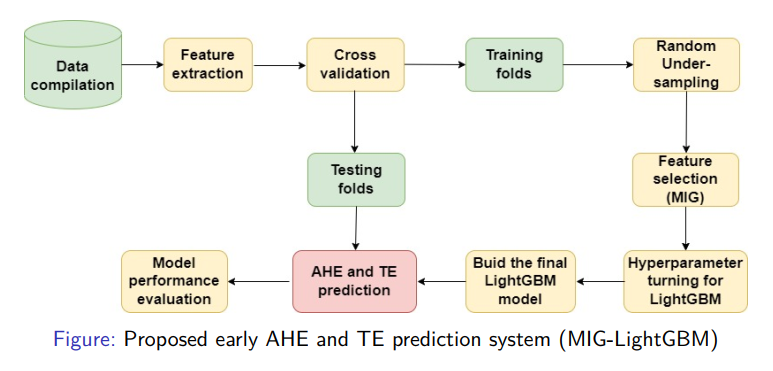
Data compilation
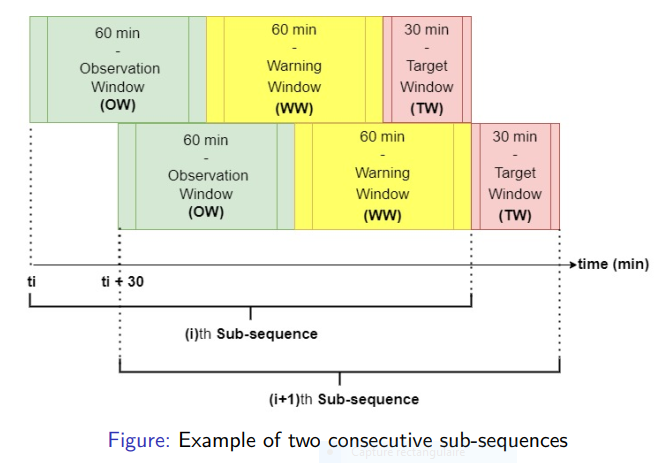
The data used in this research is a subset of the Multi-parameter Intelligent Monitoring for Critical Care (MIMIC) II database [1]. It contains minute-by-minute time series of Heart Rate (HR), Systolic Blood Pressure (SBP), Diastolic Blood Pressure (DBP), and Mean Arterial blood Pressure (MAP) arranged into records, each of which corresponds to an adult patient’s ICU stay. The dataset was traversed by sub-sequences, each one being subdivided into three windows:
Target Window: The period during which a Critical Health Event can occur.
Observation Window: Observation period containing data to be used to predict what will happen in the Target Window.
Warning Window: The gap between the Observation Window and the Target Window.
Feature extraction
Feature extraction, also known as feature engineering, is the process of extracting features from raw data using domain expertise. The objective is to utilize these extracted features to increase the quality of a machine learning model outputs when compared to simply giving the raw data to the machine learning model. In this work, the feature extraction process was carried out according to three techniques.
Knowledge-based features.
Statistical features.
Cross-correlation features.
Wavelet features.
The total number of features considered for the analysis was 111
Feature Selection
Feature selection is an important phase in data cleaning. It not only removes the redundant data but also aids in the discovery of the most relevant ones, hence improving the model’s performance. Apart from the feature importance ranking provided by the proposed predictive model, the Mutual Information Gain approach was also used for the feature selection process.
Mutual Information Gain:
Mutual Information Gain (MIG), as one of the most efficient feature selection methods, is a measure of the “mutual dependency” of two random variables. MIG creates a quantifiable link between a feature and the target. Using MIG as a feature selector has two advantages: It is model-neutral, which means it can be applied to a wide range of machine learning models; and it is also fast.
Let xj be a feature and y the target variable. The Mutual Information Gain for the two discrete random variables xj and y is given by
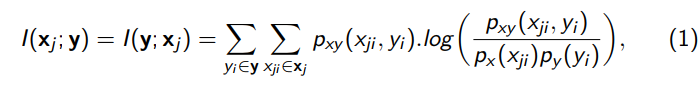
where px and py are the marginal probability and pxy is the joint probability.
It is strongly related to the notion of entropy. This is due to the fact that it may also be defined as the reduction of uncertainty of a random variable if another is known. The definition of I(xj; y) can be rewritten as:
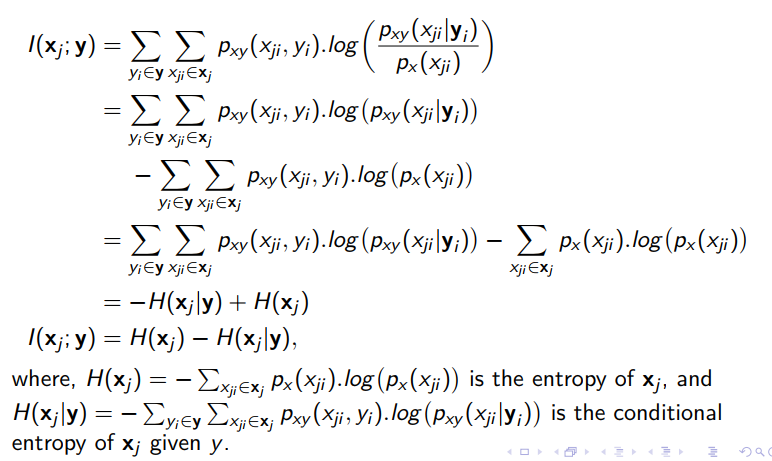
Given a set of features $X_S = {x_1, …, x_n}$ and a single feature y, the Joint Mutual Information between them is given by
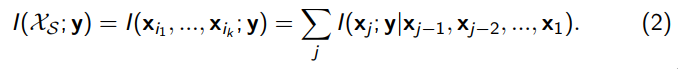
A process for selecting a subset of important features
Let |S| = k. be the number of features to be selected. The feature selection process should identify a subset of features XSˆ = {xi1, …, xik}, which maximizes the Joint Mutual Information I(XS; y)) between the class label y and all possible feature subsets XS of size k
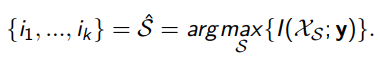
Greedy forward step-wise selection
According to their Mutual Information with respect to the target y, the features are ranked. The top feature is then selected.
Let XSt−1 = {xi1, …, xit−1} denote the set of features that were chosen at step t − 1.
Choose the next feature xit in such a way that the greatest improvement in Joint Mutual Information is achieved by using XSt. So,
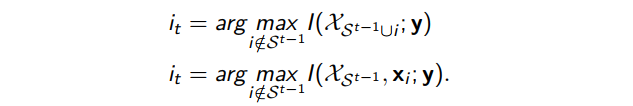
Predictive model
The Light Gradient Boosting Machine (LightGBM) is the predictive model used in the proposed early detection of AHE and TE system. LightGBM is a sophisticated Gradient-Boosted Decision Tree (GBDT) method that is designed to identify the optimal feature splitting points while also reducing the quantity of samples and features. Gradient-based One Side Sampling (GOSS) and leaf-wise growth are its two key benefits.

Gradient-based One Side Sampling (GOSS)
Key insight: Data instances with stronger gradients play larger roles in information gain computation. So, it preserves data instances with big gradients and randomly picks data with small gradients when determining the optimal split. To do so:
First, GOSS ranks the training instances based on the absolute values of their gradients.
Then, it selects the top a% of the total instances with the largest gradient. (a subset A is thus obtained)
Random sampling b% of instances from the remaining (1 − a)%. (another subset B is obtained)
The gradients of the b% of instances are multiplied by $(1 − a)/b$ , which amplifies the contribution of samples having small gradients.
Finally, the instances are split based on the projected variance gain $V^j(d)$ over the subset of selected instances:
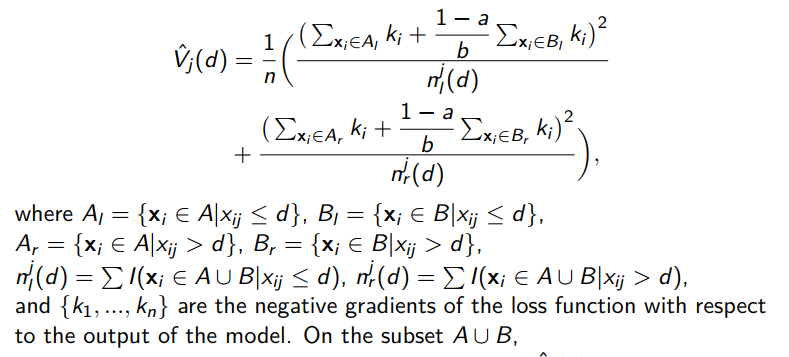
For each feature j, GOSS selects $d_j^∗ = argmax_dV^j(d)$. The data is then split based on the feature $j^∗ = argmax_jV^j(d_j^∗)$ at the point $d_j^∗$.
Leaf-wise growth
In LightGBM, the leaf-wise tree growth chooses the leaf that minimizes loss the most and splits only that leaf, ignoring the rest of the leaves at the same level. As a result, the tree becomes asymmetrical, and additional splitting may occur only on one side of the tree.
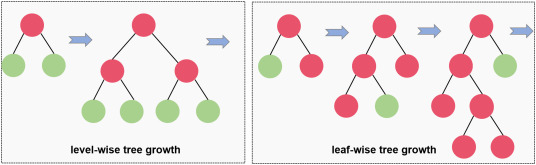
There are another two reasons why LightGBM is very fast: Histogram-based splitting and Exclusive Feature Bundling (EFB).
Histogram-based splitting
It separates the data into a given number of bins of uniform length, and then iterates across these bins to determine the best split point. So, the complexity of the algorithm goes from $O(data × features)$ to $O(bins × features)$, with $bins « data$.
Exclusive Feature Bundling
This technique identifies and combines the mutually exclusive features (features that never take zero values simultaneously) into a single feature to decrease the complexity to $O(bins × bundle)$, with $bundle « features$.
Evaluation Metrics
In this study, a model is considered to be a highly efficient algorithm for the early prediction of Acute Hypotensive Episodes and Tachycardia Episodes, if it presents a high Event F1-score (EF1-score) with a large average Anticipation Time (aveAT), and a low average False Alarms.
Event F1-score (EF1-score): It assesses the ability of the model to recognize the main events in time while avoiding false alarms as much as possible..
Average Anticipation Time (aveAT): It is the average interval of time left in advance by the model to correctly predict a Positive Case.
Average False Alarms (aveFA): The average number of false alarms launched by the system per subsequence
Results and Discussion
In order to conduct a comparative study on LightGBM and other predictive models, the Extreme Gradient Boosting (XBoost), Naive Bayes (NB), and Support Vector Classification (SVC) have also been used.
AHE early prediction
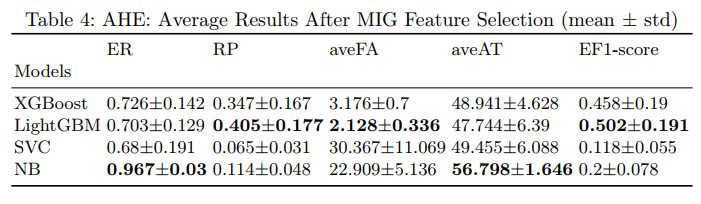
The MIG-LightGBM approach can capture up to 70% of the Acute Hypotensive Events at more than 1 hour 47 minutes before their appearance while maintaining the highest EF1-score of 50%, and the lowest aveFA of 2.1 compared to other methods.
TE early prediction
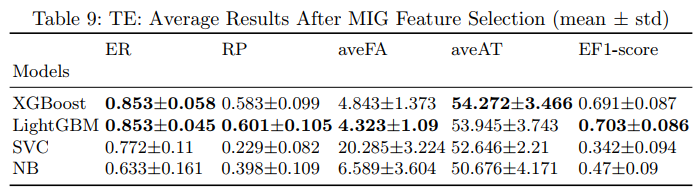
MIG-LightGBM can capture up to 85% of the Tachycardia Events at more than 1 hour 53 minutes before their appearance while maintaining the highest and remarkable EF1-score of 70%, and the lowest aveFA of 4.3
Layered Learning(LL) - VS - MIG-LightGBM
The MIG-LightGBM approach completely dominates the LL method with the main efficiency measurement metrics (EF1-score, aveAT, and aveFA). It notably exceeds LL by about 20% on both EF1-score and RP for the AHE prediction and by 50% for the TE prediction.


The proposed method, MIG-LightGBM, is therefore a highly efficient approach for the early prediction of AHE and TE. Its greatest strength is its ability to identify numerous Critical Health Episodes earlier while avoiding false alarms as much as possible, and more than existing methods. It gives ample time for vital actions to be taken after an impending alarm, and its warnings are highly reliable.
Conclusion
This study focused on building a highly effective early warning system for the Critical Health Episodes (CHEs) such as Acute Hypotensive and Tachycardia. This system is able to predict them earlier with great efficacy, while avoiding false alarms as much as possible. In practical situations, it can be applied on patients to make a reliable early prediction on Critical Health Episodes, having knowledge of at least their latest one-hour observations. But this system can sometimes omit some Critical Health Episodes. A direct future work can therefore focus on strengthening more the system’s ability to identify CHEs.
REFERENCES
[1] Hotegni, S.S. and Fokoué, E., 2022. Efficient Novelty Detection Methods for Early Warning of Potential Fatal Diseases. arXiv preprint arXiv:2208.04732.
[2] https://github.com/salomonhotegni/MasterThesisAIMS
